Introducing Inverse Generative Social Science

For three days this week I have been glued to Zoom, taking part in the Inverse Generative Social Science (IGSS from now on, its a mouthful) workshop 2021. Work was put on hold. Noise-cancelling headphones were fixed to my head. It was a blast of information and new perspectives, everything from foundational frameworks and questions to specific model implementations. Unfortunately, the framework of generative social science (GSS) is not a commonly taught one (yet?). This is my attempt at a somewhat coherent introduction to these ideas.
Generating a Phenomenon
What exactly is generative social science? Generative social science (GSS) is a philosophy and a framework for seeking explanations in the social sciences.
Consider a social scientist who observes a macroscopic regularity M. For instance, housing prices, business cycles, or voting outcomes. In other words, aggregate outcomes over time.
The researcher then explores causality by asking how M changes over time. More precisely, the researcher is trying to ascertain the functional form of f(). The complex nature of economic problems means this typically includes other macro outcomes B, e.g. how income inequality affect housing prices, or even meso-outcomes, like the production of different industries. By and large, however, it remains at an aggregate level.
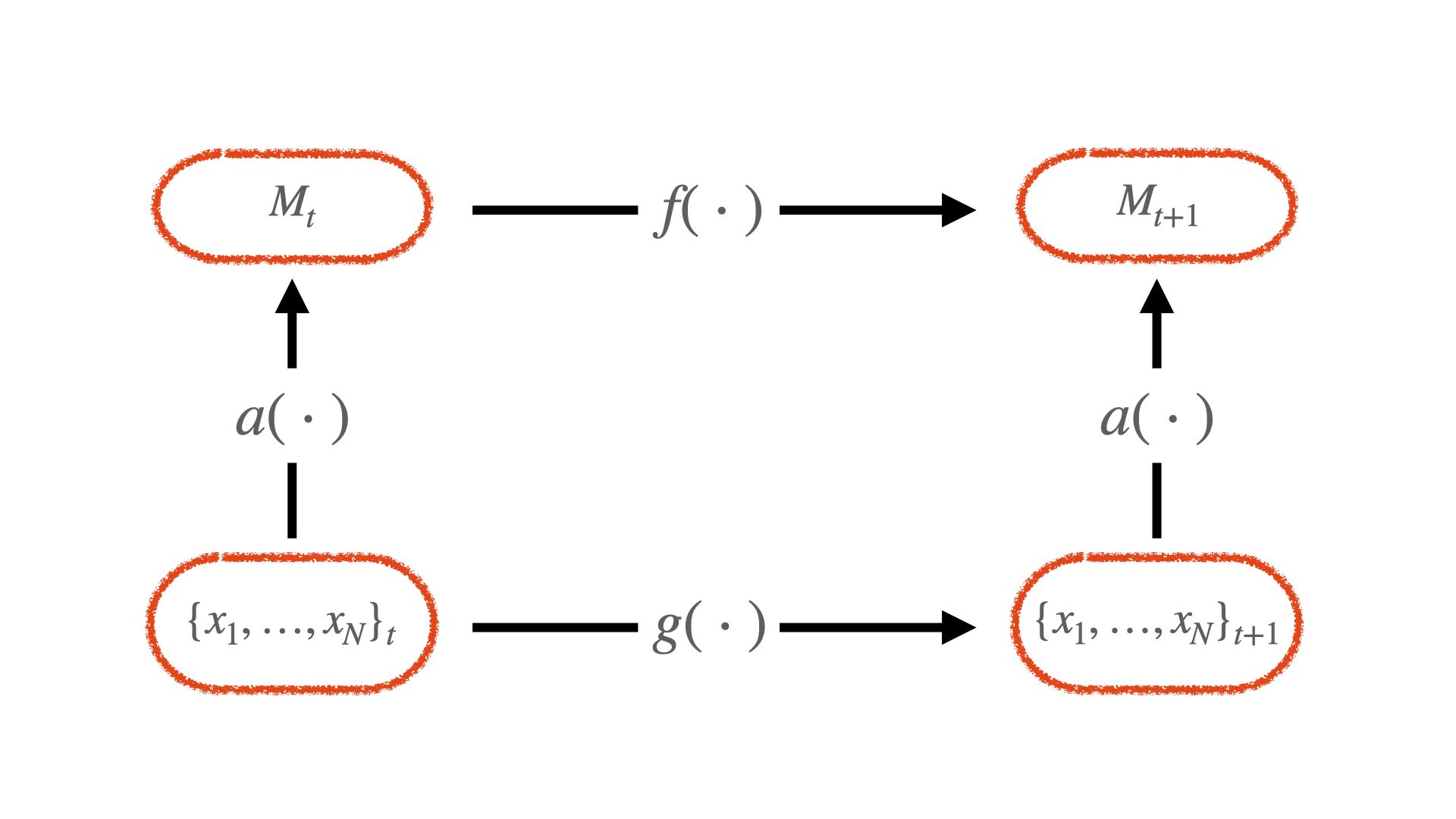
We can depict this via analogy to Coleman's boat. The researcher posits a model for f() is at the aggregate level. However, as Coleman suggests, "the macro level is an abstraction, nevertheless an important one" (Foundations). The generating causal structure is g(), which relates the micro-agents to one another over time, and transforms to the macro via aggregation a().
To a generativist social scientist, only once g() is illuminated can the relation be accepted as an explanation. A generativist thus asks
How could the decentralized local interactions of heterogeneous autonomous agents generate the given regularity? (Epstein, 1999)
and accepts an explanation of a particular form, where they
Situate an initial population of autonomous heterogeneous agents in a relevant spatial environment; allow them to interact according to simple local rules, and thereby generate—or “grow”—the macroscopic regularity from the bottom up (Epstein, 1999)
Put simply, it is the motto
If you didn't grow it, you didn't explain it
Agent-based Models
What does this look like in practice? The tool of generative social science is agent-based modeling. Simply put, we postulate all of the agents, their behavior, the institutional framework, and the aggregation mechanisms. These are then simulated using a computer because the dynamics are complex and not easily mathematically solved.
Given the outcomes of the simulation, we can then analyze the outputs, compare the macro- and meso-outputs to empirical data such as GDP series, and validate the model.
I won't go into the principles of Agent-based models here, as that would be too long of a post. You can refer to some pointers for agent-based modelling for macroeconomics here.
Generative Explanation: Micro to Macro
So a generative explanation posits a micro-specification that leads to observed aggregate outcomes. In the image above, that means we posit some set of agents, x, and the forms in which they behave and interact, g. This is then iterated forward in time to generate aggregate dynamics (recall we can simply aggregate the micro-agents). This is a forward process: posit behavior, assess outcome. Visually
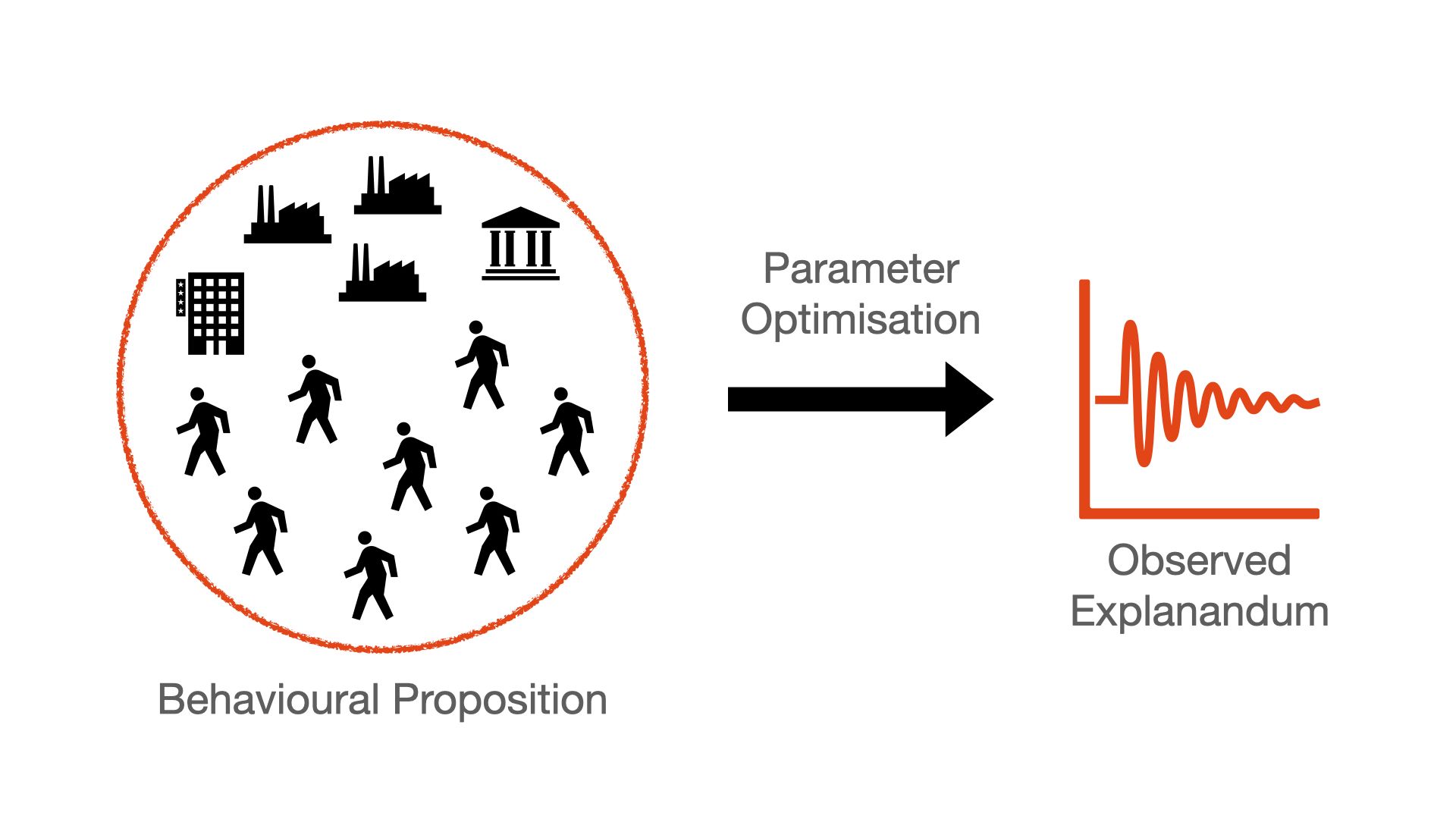
What's the rub? Identification. There are a lot of different behavioral propositions that may lead to the same observed explanandum. In the words of Sims, we have arrived in the wilderness of bounded rationality. This is a critique often leveled against the behavioral assumptions of agent-based models.
There are means to narrow down our search. We could introduce data about more different macro-dynamics for the same set of agents. We could introduce data at more granular scales, down to the agents themselves. However, this has natural limitations, since data availability is limited.
What about inverse GSS?
Inverse Generative Social Science (IGSS) addresses the issue of possible generating behaviors g(). GSS posits a single form for the micro behavior, g(), and tests if this valid. With Inverse GSS we instead ask: "What are the possible behaviors that can generate the aggregate dynamics f()?"
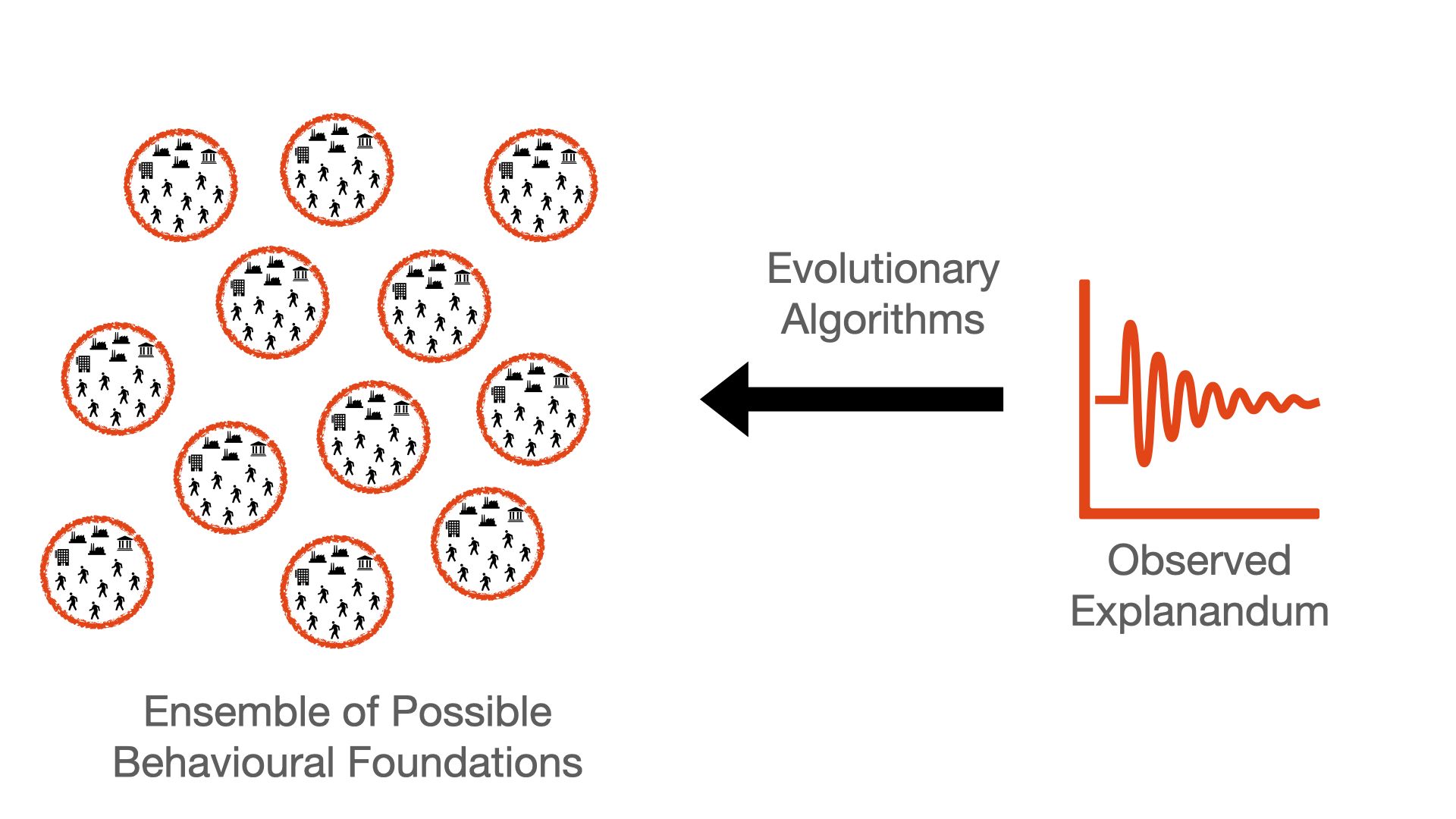
The outcome of this approach is a set of all relevant behavioral foundations. One could then use alternate data or field experiments to see whether this behavior is reasonable. Should the set of possible generating behavior be reasonable and diverse, we could even move to say that the aggregate dynamic is robust to behavioral changes. One thing that would intrigue me is to also study how these behaviors are related, and whether there is an underlying basis.
Is learning the ensemble of behavior too big a task?
It is certainly a daunting one. Attempting to do this for all the decisions of each agents in an agent-based model might not be a fruitful endeavor. Instead, we should try to infer a single class of agents behavior while keeping the remaining model constant. For example, the household's consumption behavior, or where they choose to buy houses.
I imagine the application of IGSS to economics to begin with single agent types. We have a set of well-founded economic models of economic aggregates. The idea behind those dynamics are based on agents, be that households, firms, or banks, decide. For instance, we relate debt levels are to banks' willingness to lend money.
Let us choose a class of agents, say banks, and create an agent-based version of the financial system where each bank is an agent. This is called agentization, and allows us to apply IGSS to answer the questions: (1) Which types of behavior lead to the same outcomes as the original aggregate model? (2) What kind of behavior leads to the observed empirical data? The outcome of this study would be two sets of possible behavior that can then be studied: Is there are a general behavioral structure in each set? Can we further reduce the set through other data or experiments? This study limits which behavior to infer, which improves the feasibility and interpretability of the results.
The handy side-effect is also building up the study of inequality and distribution. With only a single agent or aggregate variable, this is hard to do. If we are adding agents already anyway...
Does inferring behavior work?
This is a research area in its infancy, but the results have been extremely promising, and include: Evolutionary Model Discovery (Gunaratne), Rule Induction (Rand), Computational Abduction, and others. OK, but that doesn't mean much without some examples....
At the IGSS workshop 2021 there were multiple examples of how an ensemble of behavioral rules were inferred for polarization in social networks and flocking behavior, the slides do a better job of explaining this visually than I would do here. Suffice it to say, this is a growing research area. The question is when and how can we use this in economics? Can we infer household or firm behavioral decision-making rules from the data, and which theoretical approaches will this validate?
Curious to know more?
Keep an eye out for next year's IGSS workshop, and enjoy the presentations of the 2020 & 2021 workshops at https://www.igss-workshop.org/




